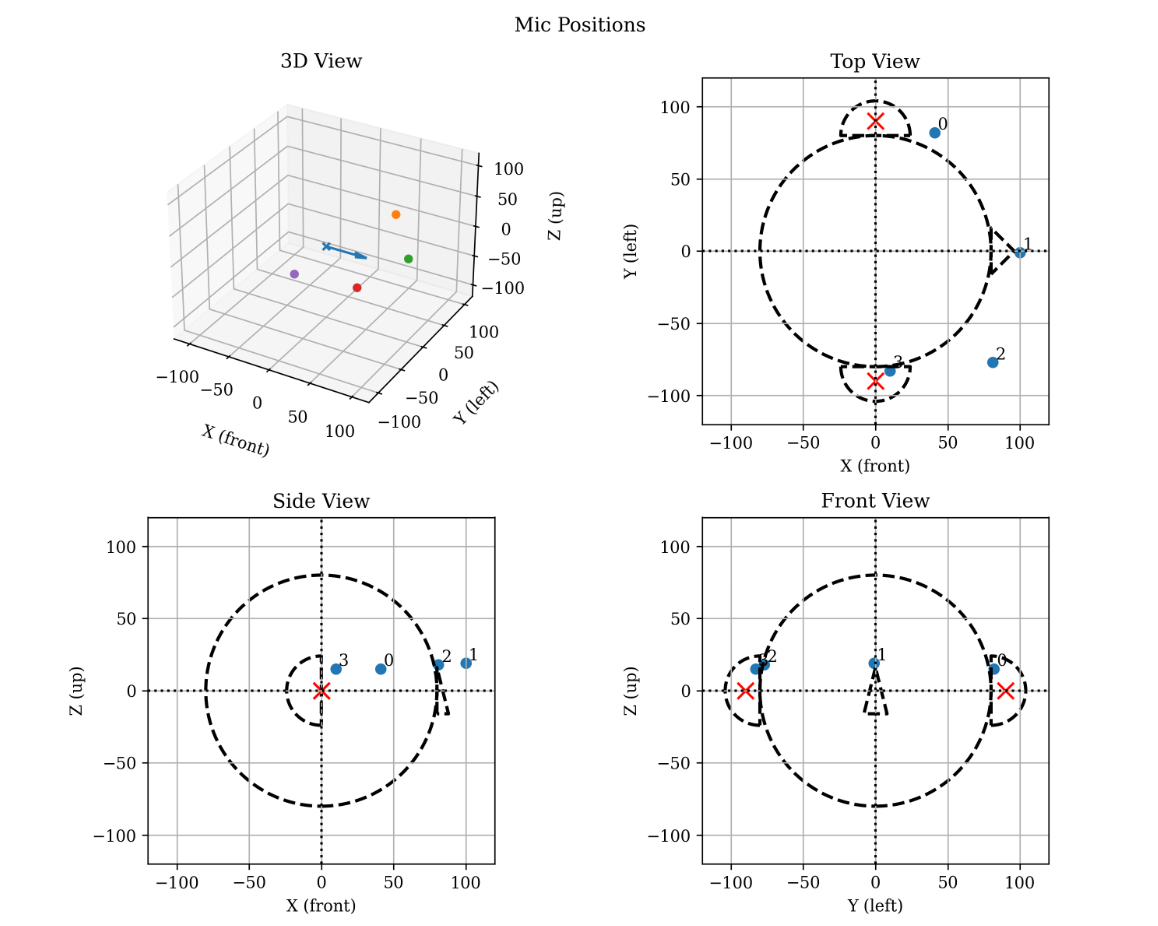
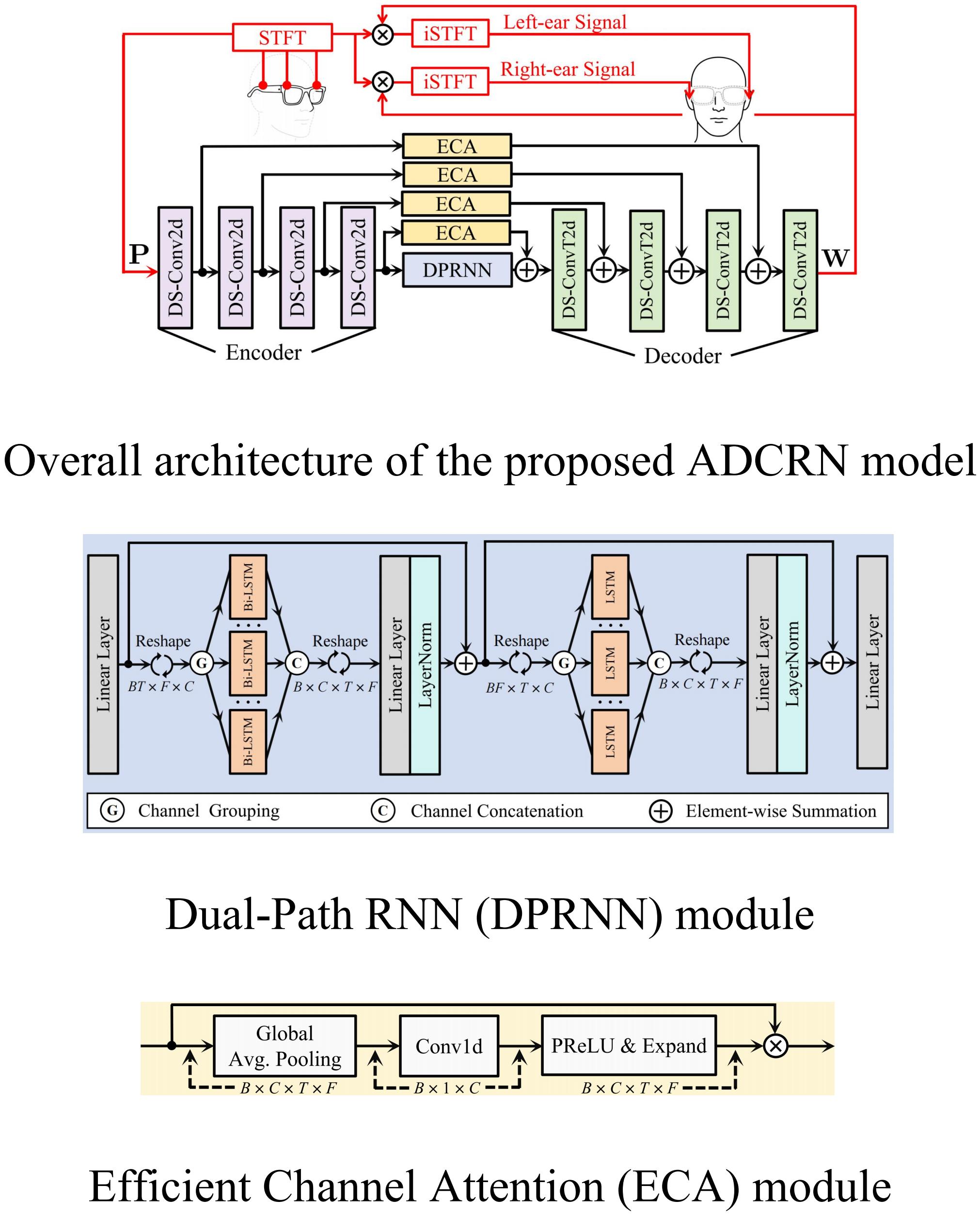
ADCRN: A Lightweight Neural Network for Binaural Reproduction on Head-Mounted Devices
Tianyou Li*, Xiaobin Rong*, Junjie Shi†, Huiyuan Sun†, Xiaohuai Le†, Chuanzeng Huang†, Jing Lu* * Key Laboratory of Modern Acoustics, Nanjing University · † ByteDance
ABSTRACT
Binaural reproduction (BR) on head-mounted devices (HMDs) converts microphone recordings into binaural signals.
Conventional binaural signal matching (BSM) predicts BR filters from predefined source distributions but degrades under mismatch.
Recent DNN-based BR improves content accuracy and spatial fidelity, yet often with heavy parameters and compute, and their effectiveness on HMDs is under-explored.
This demo presents a lightweight Attention-enhanced Dual-path Convolutional Recurrent Network (ADCRN) with a dual-path recurrent bottleneck for temporal–spectral modeling and efficient channel attention for cross-channel recalibration.
On simulated datasets from AR-glasses arrays, ADCRN achieves state-of-the-art objective and subjective performance with fewer parameters and lower computational complexity.
Note. For accurate binaural playback, please use wired stereo headphones connected directly to the device (disable any spatialization, EQ, or audio enhancements). Listen carefully for perceived source direction and spatial realism.
RT60
Reference
ADCRN (Proposed)
MDFNet
LS
MagLS
iMagLS
0.1 s
0.4 s
0.65 s
0.9 s
1.2 s
3. Subjective evaluation: setup and results
MUSHRA setup
We conduct a MUSHRA test under five reverberation conditions with RT60 values of
0.1 s, 0.4 s, 0.65 s, 0.9 s, and 1.2 s. In each condition, each trial presents stimuli of the same utterance,
including a hidden reference, a degraded anchor obtained by applying a 3.5 kHz low-pass filter to the reference,
and the outputs of five methods, namely the proposed ADCRN, MDFNet, and three BSM baselines.
The presentation order is randomized within each trial. Listeners rate spatial fidelity on a scale from 0 to 100,
with higher scores indicating closer agreement with the reference in terms of both audio quality and perceived source localization.
A total of 25 subjects participate in the subjective listening test.
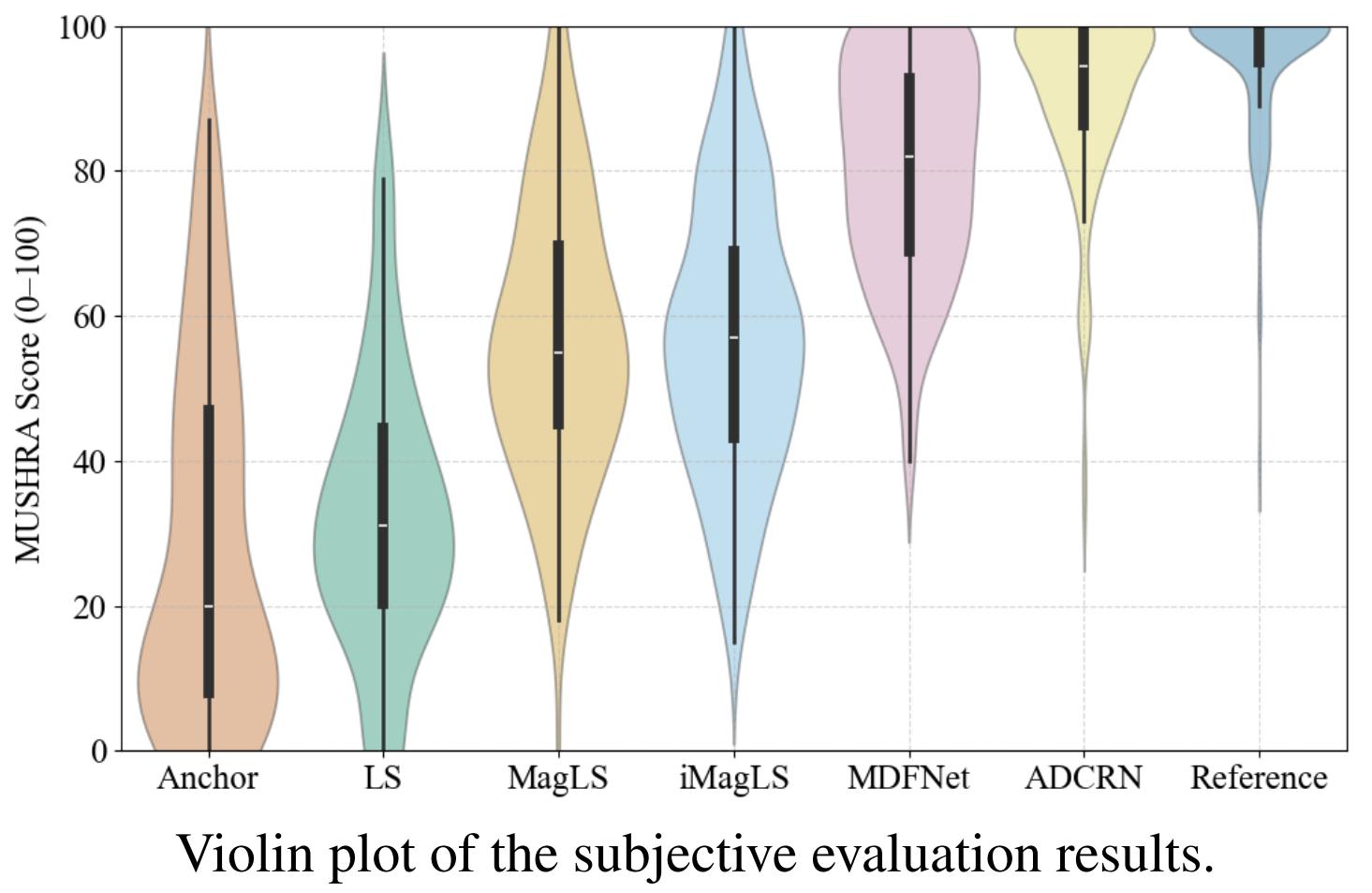
MUSHRA results
Conclusion:
Subjective evaluation results further validate the superiority of the proposed ADCRN model in terms of perceptual quality and spatial realism.
ADCRN consistently receives ratings approaching those of the reference, with a concentrated distribution near the upper bound (above 90),
indicating strong listener preference and high spatial fidelity. Compared to the BSM-based baselines (LS, MagLS, iMagLS), ADCRN shows
substantial perceptual improvements, while also outperforming MDFNet despite its significantly lower model complexity. These results confirm
that the ADCRN-rendered binaural signals not only match reference quality objectively, but also provide an immersive and perceptually
faithful spatial audio experience.